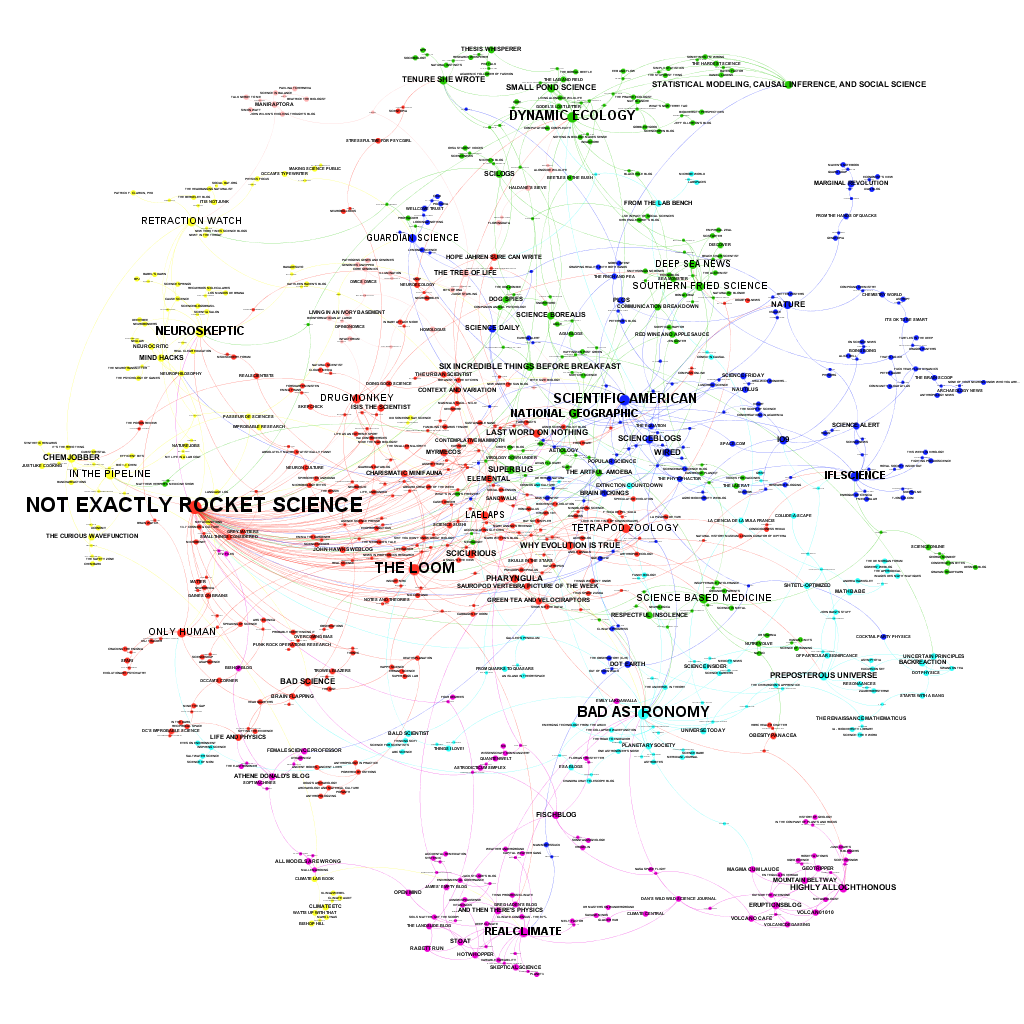
Paige Brown Jarreau performed a survey among science bloggers. A first result is the fascinating network analysis of science blogs shown above. She also published a PDF where you can zoom in to look at the details. The survey asked every blogger to list three other regularly read science blogs. In the figure above the blogs are the dots and every mention is a link between the dots. The more incoming links, the bigger the dot and name. The links do not show in which direction the link runs. The smallest print is for blogs that participated, but have no incoming links.
Clearly dominating is the blog Not Exactly Rocket Science by Ed Young. Also influential is Bad Astronomy by Phil Plait, who also blogs about climate and the "climate debate". Except for these two outliers, the network is surprisingly egalitarian.
There is likely a sampling bias, but the small number of non-english blogs is striking.
For us the climatic part of the blog universe is naturally most interesting.

Here RealClimate clearly dominates. Even if they are not that active anymore and are calling for a new generation of climate scientists to help them continue high-quality climate science blogging.
One should be very careful to interpret the details. My little blog is only more visible than the blog of the more important International Surface Temperature Initiative because I have one incoming link. Such details can thus quickly change when more bloggers had participated or more than 3 blogs could have been mentioned.
Emphasized by the automatic coloring scheme is the splendid yellow isolation of WUWT & Co. If there would be no link between WUWT and the Climate Lab Book, they would have no link to science whatsoever. This network analysis could be used to determine who is eligible for a bloggie in the category science.
[UPDATE 3: The WUWT cluster looks large, it has 8 blogs and many links between them, but this feature is less robust than you would thus think. It is only based on the responses of 3 bloggers. Had I thought of that before, I would have chosen a more careful title.]
Here it should probably be mentioned that a link is not necessarily a recommendation. I know of some US climate scientists that keep an eye on WUWT to know of the latest nonsense story before the journalists start calling. You can be sure that they do not read WUWT to learn about the climate system. The isolation was to be expected given the quality standards at WUWT, which do not fit to science.
On the other hand, the purple climate and geo sciences cluster is clearly well embedded in the scientific community. The blogs Climate Etc. and Klimazwiebel often talk about building bridges to the mitigation sceptics. Maybe they should put a bit more emphasis on building bridges to the scientific community. (And I sometimes wonder why they do not want to build bridges to alarmist activists as well.)
[UPDATE 1: William M. Connolley reports on this post at Stoat and unfortunately emphasizes the presence of Mark Lynas and the Klimazwiebel in the yellow cluster. Both depends on only one link, on only one blogger mentioning them. Such details should not be taken seriously. The yellow cluster having little interaction with science blogs would likely remain if a bigger sample were available, but details about single little-mentioned blogs could completely change.]
More activist blogs, such as Georg Monbiot and Desmog Blog are not in the climate cluster, but can be found on the middle right as a green cluster.
[UPDATE 2: There are now several blog posts on this topic.
Stoat (William M. Connolley) and Climate Etc. (Judith Curry) summarize this post. The comment section at CE is, again, very ugly, full of personal attacks, which is the response of last resort if you do not have any arguments. Fitting to the isolation of the WUWT & Co cluster is that the Stoat post gives me more visitors than the post at Climate Etc. While for a Climate Etc. reader it would make more sense to expect that my post is misrepresented and thus to click on the link to check what was really written. And just like WUWT, Climate Etc. is proud of the large amount of comments and clicks; Judith Curry in 2010: "If what I said was utter nonsense, why is anyone here talking about it, I have 440 comments in 24 hours." If CE is really so big, it certainly has more comments, you would expect more, not less, readers coming from there.
Lucia at The Blackboard reports about the Climate Etc. post with the funny title: HotWhopper’s Sou Doesn’t read WUWT!
A smart observation. Lucia is highly intelligent and a fierce debater. The climate "debate" would be more interesting if she would run WUWT. Unfortunately, she seems to see the climate "debate" as a sport. If she were more interested in improved understanding, I would read her blog often.
While it is a smart observation, the simple reason for the perceive discrepancy may be:
@VariabilityBlog As bloggers were asked which science blogs they read, no surprise Sou didn't list WUWT - it's not a science blog
— Louise Mothersole (@lrmothersole) December 30, 2014And indeed, Sou from HotWhopper writes (Hat tip Lucia in her comments):
The blog I probably visit most frequently I didn't list - because I don't rate it as a science blog, although I see that it appears on your map.I mentioned:
And Then There's Physics: A great place for intelligent conversation on climate and the climate debate.
HotWhopper: A good place to keep up to date with what happens at WUWT without having to read the misinformation. Sometimes you do not remember where you got some information from, you might think it was a reliable source, whereas it was WUWT. I already embarrassed myself among colleagues by repeating something I had learned at WUWT and could not imagine being wrong, being so basic, but it was. Best to limit your exposure, to keep your brain healthy.
Real Climate: If there is a new RealClimate post that is likely to be a good investment of my precious life time and I read a large part of them to keep up to date with the state of the art in fields where I do not work on myself.
Lucia also wondered why I did not mention WUWT. I do not know anymore. Maybe because the question was about science blogs and WUWT is a political blog. The reaction of WUWT to a new piece of research can be predicted extremely well by considering whether it makes the political case for mitigation stronger or weaker. On a science blog, the reaction would depend on the quality of the research and whether the conclusions are justified by the evidence presented.
Maybe I also just did not mention WUWT because reading it is not a high priority. But I have never denied reading WUWT occasionally. When I read it, more out of interest as blogger. It is the voice of mainstream mitigation skepticism.
It is probably not a good idea to interpret single links and sizes of blogs. You should probably not even interpret the size of the clusters due inherent problems with sampling and because blogs in the cluster of WUWT & Co might not have seen themselves as the target group.
It is still interesting that the only link between the WUWT & Co. cluster to the rest is Ed Hawkins stating to read WUWT. None of the sampled blogs in the yellow cluster have reported themselves to read blogs outside of their cluster. The "isolation" is, in this respect, self-selected. In this regard, it is somewhat strong that mitigation skeptics complain about me showing this network.
If the sample were bigger, some links may have appeared. And there might be weaker links; had the question asked for a larger list of blogs, these links may have appeared, but the cluster would likely have stayed quite self-referential. I would expect that that part of the network analysis is robust and that is why I emphasized that part.
The survey was about what motives science bloggers. This network is interesting, but "just" a side result that should not be over-interpreted.]
Tweet
Related reading
A Network of Blogs, Read by Science Bloggers. Here Paige Brown Jarreau (The Lab Bench) explains more details of the network analysis and shows a plot with all the blogs in the purple climate/geo science cluster.The figures can be found at Figshare.
You can play with this data via an interactive Gephi graphic here: bit.ly/MySciBlogREAD, which also gives you links to the blogs to find new interesting ones.
Stoat: Tee hee
Readership of all major "sceptic" blogs is going down. (WUWT has already removed all independent counters.)
The BBC will continue fake debates on climate science.
Interesting what the interesting Judith Curry finds interesting.